
La inteligencia artificial ha dejado se ser un término abstracto para estar presente en prácticamente todos los ámbitos de la sociedad, incluyendo por supuesto a los mercados de valores. En esta entrada del Glosario de FundsPeople explicamos en qué consiste esta tecnología y las diferentes maneras de aplicarla.
¿Qué es?
En términos sencillos, la Inteligencia Artificial es la simulación de la inteligencia humana por máquinas. Los programas informáticos que aprovechan grandes cantidades de datos y cálculos se entrenan para realizar tareas como la toma de decisiones y la resolución de problemas con una intervención humana mínima. Los algoritmos de Inteligencia Artificial suelen basarse en reglas y se construyen mediante un procesamiento iterativo para reconocer patrones y hacer predicciones. La evolución de tecnologías como la nube, la computación y el big data han contribuido a que la Inteligencia Artificial sea más rápida, barata y accesible.
¿Qué tipos hay?
En el white paper publicado por Goldman Sachs bajo el título Generative AI - Part I: Laying Out the Investment Framework, los autores del estudio explican que la Inteligencia Artificial es un concepto amplio que engloba varios subgrupos, como el aprendizaje automático (machine learning), las redes neuronales (neutral networks), el aprendizaje profundo (deep learning) y el procesamiento del lenguaje natural (natural language processing – NPL). Todos ellos son cambios destacados dentro de la Inteligencia Artificial, que se detallan en el trabajo académico realizado por la firma americana.
Aprendizaje automático
Tal y como indican en el white paper, la Inteligencia Artificial permite a las máquinas auto-aprender mediante el entrenamiento a partir de conjuntos de datos de un modelo. Los algoritmos se entrenan para hacer predicciones e identificar patrones aprendiendo de datos históricos. Estos algoritmos se crean utilizando lenguajes de programación de machine learning.
Un ejemplo sencillo de algoritmo de machine learning es el de YouTube, que sugiere un vídeo basándose en las visitas anteriores de una persona. El proceso de enseñar al algoritmo a identificar patrones comienza proporcionándole datos de entrenamiento, que pueden ser conjuntos de datos etiquetados o no etiquetados.
Los modelos de aprendizaje automático se entrenan utilizando una de estas dos técnicas: aprendizaje supervisado o no supervisado. El supervisado es una técnica similar al aprendizaje humano. A un ordenador o máquina se le presenta un conjunto de entrenamiento que consiste en un gran volumen de conjuntos de datos etiquetados. Con el aprendizaje automático no supervisado, el algoritmo se entrena para aprender a identificar patrones a partir de conjuntos de datos no estructurados.
Después de introducir los datos en el algoritmo de machine learning se comprueba si los resultados predichos y los resultados coinciden. Si la predicción no es exacta, el algoritmo se vuelve a entrenar varias veces hasta que se obtiene el resultado deseado. El proceso de entrenamiento iterativo permite, en última instancia, que los algoritmos de machine learning aprendan continuamente y produzcan resultados más precisos a lo largo del tiempo.
- Aprendizaje automático supervisado
Se trata del aprendizaje automático basado en el entrenamiento supervisado de un modelo. Los algoritmos se entrenan utilizando conjuntos de datos estructurados y etiquetados. El modelo se entrena primero con grandes volúmenes de valores de entrada correspondientes y valores de salida esperados, y luego se aprovecha para predecir las salidas basándose en los datos de prueba. Por ejemplo, para entrenar un modelo de machine learning que reconozca la imagen de un gato, el modelo se entrena primero con millones de imágenes de gatos y otros animales para aprender a distinguir entre características como el color, el tamaño, la forma, etc. Una vez que el modelo está bien entrenado puede identificar un gato. Las aplicaciones incluyen la detección de fraudes, la segregación de imágenes, el diagnóstico médico...
- Aprendizaje automático no supervisado
A diferencia del anterior, estos modelos de machine learning no requieren supervisión y se entrenan con conjuntos de datos no etiquetados. El modelo identifica patrones, similitudes y diferencias a partir de los datos de entrada para obtener una respuesta de salida. Las aplicaciones más comunes de estos modelos son la detección de anomalías.
- Aprendizaje por refuerzo
Es similar al aprendizaje automático sin supervisión, pero reforzado con un bucle de retroalimentación automática que mejora el rendimiento del algoritmo. En el modelo no hay conjuntos de datos clasificados. Se entrena basándose en patrones y tendencias con una capa de retroalimentación añadida que refuerza el algoritmo cada vez que se genera la salida correcta, fortaleciendo así el modelo con cada ensayo.
Redes neuronales (neural networks)
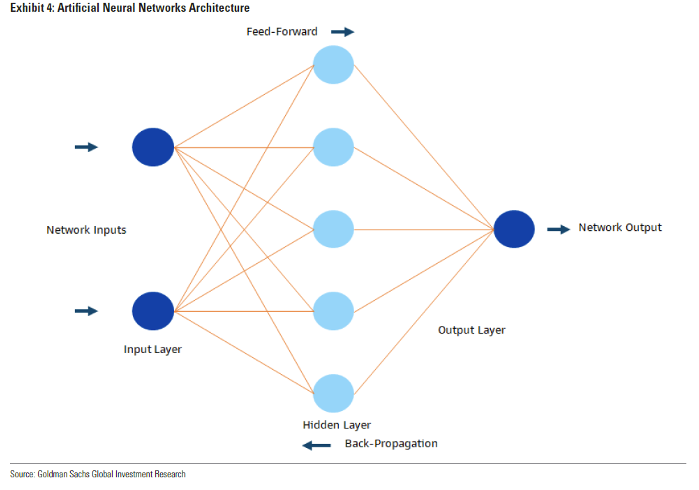
Funcionan de forma similar a las neuronas del cerebro humano. Al igual que los seres humanos procesan la información a través de una amplia y compleja red de neuronas. Una red neuronal creada artificialmente funciona sobre un sistema de múltiples nodos que procesan y filtran la información en múltiples etapas. Los datos fluyen por una red neuronal artificial (RNA) a través de un proceso feed-forward o algoritmo de retropropagación. Las redes neuronales feed-forward procesan los datos unidireccionalmente, pasando los datos del nodo de entrada al de salida.
La capa inicial de una RNA es similar al nervio óptico humano, que recibe los datos en bruto. Cada nodo posterior es un centro de conocimiento individual, que filtra y clasifica los datos en cada etapa. La salida de la capa anterior sirve de entrada al siguiente nodo, ya que cada uno predice un resultado y el siguiente evalúa si la salida anterior era correcta. La retropropagación permite que los datos fluyan a través de múltiples vías diferentes. Se asigna el peso más alto a la vía que produce las respuestas más precisas y pesos más bajos a las vías neuronales con resultados más débiles.
Al aprovechar estos bucles de retroalimentación continua, las redes neuronales artificiales mejoran su análisis predictivo. Los modelos de RNA pueden entrenarse utilizando técnicas como el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo.
Aprendizaje profundo (deep learning)
El aprendizaje automático tradicional requiere un mayor grado de intervención humana para determinar las entradas de datos correctas y el diseño de las características que debe analizar el software de machine learning. Esto limita la creatividad del algoritmo. Los algoritmos de aprendizaje profundo, por otro lado, aprenden a través de la observación de datos no estructurados y se superponen con redes neuronales artificiales que intentan simular mejor el comportamiento humano. Aprenden de forma independiente a identificar características y a dar prioridad a los atributos de los datos.
La diferencia clave entre el machine learning tradicional y el aprendizaje en profundidad es el uso de redes neuronales artificiales para entrenar el algoritmo en lugar de la intervención humana. De este modo, avanza el uso de técnicas de aprendizaje profundo sobre el aprendizaje automático tradicional.
Por ejemplo, a la hora de entrenar un algoritmo que identifique la imagen de un gato a partir de un gran conjunto de imágenes de animales. Un ser humano tendría que decirle al algoritmo de machine learning que identifique características como la forma de la cola del animal, la oreja, el color del pelo, el número de patas, etc. Sin embargo, para el entrenamiento de un algoritmo de aprendizaje profundo, la RNA procesaría el conjunto de imágenes subyacentes. Determinaría las características que deben evaluarse y el orden de prioridad en que deben hacerlo para generar el resultado más preciso.
Procesamiento del lenguaje Natural (natural language processing- NLP)
Antes sólo se podía comunicar con un programa informático mediante código. Con la evolución del NPL, las máquinas pueden comunicarse con los humanos en su lenguaje natural. El Procesamiento del Lenguaje Natural permite a los ordenadores interpretar el habla, medir el sentimiento y leer textos. Para que las máquinas puedan entender el lenguaje humano, la NPL utiliza dos técnicas: el análisis sintáctico y el semántico.
- El análisis sintáctico identifica la estructura y la relación entre las palabras de una frase
- El semántico se centra en el significado de las palabras y la comprensión del contexto de la frase.
Los algoritmos de NPL indexan las consultas en lenguaje humano y las convierten en lenguaje máquina mediante los siguientes procesos:
- La tokenización, descomponer el texto en unidades semánticas más pequeñas; eliminar palabras como preposiciones y artículos que no aportan información adicional,
- La lematización y el stemming, que ayudan a categorizar y convertir las palabras a su raíz (por ejemplo, la palabra “mejor” se transformaría en “bueno”), y
- El etiquetado de partes del discurso ayuda a etiquetar las palabras según su contexto gramatical como sustantivos, verbos, signos de puntuación, etc.
Gracias a estos pasos, los ordenadores son capaces de comprender, analizar y traducir el texto y el habla humanos. Las técnicas de NPL se utilizan para entrenar algoritmos tradicionales de aprendizaje automático y aprendizaje profundo.
Si te interesa este tema, te recomendamos leerte el módulo Inteligencia Artificial: aplicaciones en inversión y gestión de carteras de FundsPeople Learning realizado en colaboración con Allianz Global Investors.